图 (Graph)
图 (Graph)
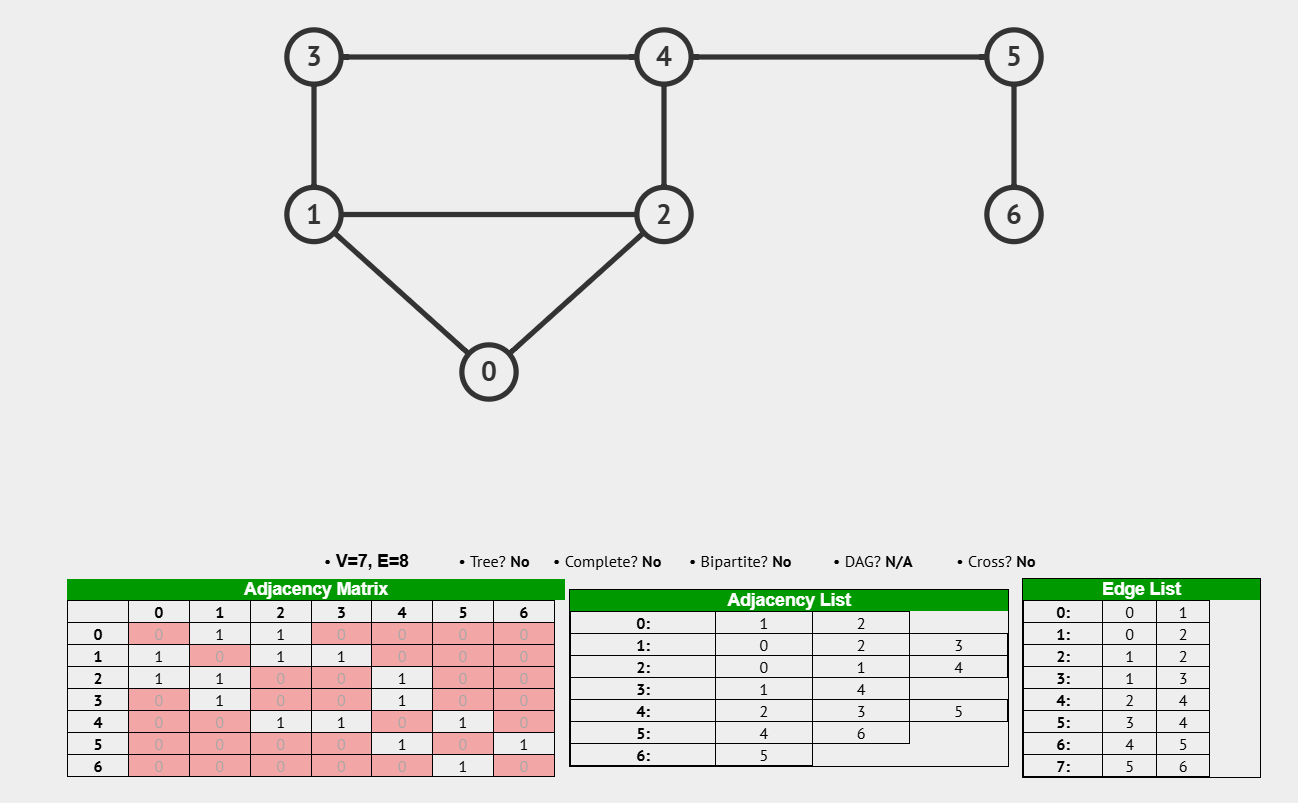
概念:由节点 (Vertex) 和边 (Edge) 组成,表示对象之间关系的数据结构
图 (Graph) 是一种比树结构更通用的数据结构,它可以用来表示 对象之间复杂的关系网络。 例如,社交网络中人与人之间的关注关系、城市交通网络中城市与城市之间的道路连接、计算机网络中计算机之间的连接关系等等,都可以用图来表示。 图主要由两个基本元素组成:
- 节点 (Vertex / Node): 图中的基本单元,代表对象或实体。 例如,在社交网络图中,节点可以代表人;在交通网络图中,节点可以代表城市。 节点有时也称为 顶点。
- 边 (Edge): 连接图中两个节点的线,表示节点之间的关系。 例如,在社交网络图中,边可以表示两个人之间的关注关系;在交通网络图中,边可以表示两个城市之间的道路。
类型 (Types)
根据边的性质和方向,图可以分为不同的类型:
有向图 (Directed Graph): 边是有方向的,表示关系是单向的。
如果图中有一条从节点 A 到节点 B 的有向边,表示从 A 到 B 有一个方向的关系,但 不一定 有从 B 到 A 的关系。
有向边通常用带箭头的线段表示,箭头指向关系的方向。
示例:
- 网页链接: 网页 A 上的链接指向网页 B,表示从网页 A 可以跳转到网页 B,但反过来不一定能从网页 B 跳转回网页 A。
- 关注关系: 在微博、Twitter 等社交媒体中,用户 A 关注了用户 B,表示 A 可以看到 B 的动态,但 B 不一定关注 A。
- 任务依赖关系: 任务 A 的完成必须依赖于任务 B 的完成,表示任务之间存在先后执行的依赖关系。
无向图 (Undirected Graph): 边是没有方向的,表示关系是双向的。
如果图中有一条连接节点 A 和节点 B 的无向边,表示 A 和 B 之间存在某种关系,且这种关系是 相互的。 无向边通常用不带箭头的线段表示。
示例:
- 城市道路: 城市 A 和城市 B 之间有道路相连,表示可以从城市 A 开车到城市 B,也可以从城市 B 开车到城市 A。
- 朋友关系: 在社交网络中,用户 A 和用户 B 互为好友,表示 A 是 B 的朋友,同时 B 也是 A 的朋友。
- 化学分子结构: 化学分子中原子之间的化学键连接,表示原子之间相互作用。
总结: 区分有向图和无向图的关键在于 边是否有方向,以及关系是否是单向或双向的。 在实际应用中,需要根据具体场景选择合适的图类型来表示数据关系。
表示方法 (Representation Methods)
图数据结构需要在计算机中存储和表示,常见的图表示方法有两种:
邻接矩阵 (Adjacency Matrix):
邻接矩阵 使用一个 二维数组 (矩阵) 来表示图中节点之间的邻接关系。
假设图有 n 个节点,邻接矩阵就是一个 n x n 的矩阵,矩阵的元素
matrix[i][j]表示节点i和节点j之间是否 存在边。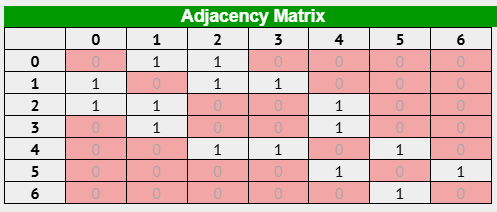
表示规则:
- 对于 无权图 (边没有权重),通常使用 布尔值 (0 或 1) 或 整型值 (0 或 1) 来表示邻接关系。
matrix[i][j] = 1(或true):表示节点i和节点j之间 存在边。matrix[i][j] = 0(或false):表示节点i和节点j之间 不存在边。
- 对于 带权图 (边有权重),
matrix[i][j]可以存储节点i和节点j之间 边的权重值。 如果节点之间不存在边,可以使用一个特殊值(例如,无穷大 ∞ 或 0,取决于权重是否非负)来表示。 - 对于 无向图,由于边是双向的,邻接矩阵是 对称矩阵,即
matrix[i][j] == matrix[j][i]。 - 对于 有向图,邻接矩阵 不一定是对称矩阵,
matrix[i][j]表示从节点i到节点j是否存在边,matrix[j][i]表示从节点j到节点i是否存在边,两者可能不同。 - 节点到自身的边 (环) 可以用
matrix[i][i]表示。 通常,无向图的邻接矩阵对角线元素为 0,有向图根据具体情况而定。
- 对于 无权图 (边没有权重),通常使用 布尔值 (0 或 1) 或 整型值 (0 或 1) 来表示邻接关系。
优点:
- 简单直观: 邻接矩阵表示法非常直观,容易理解和实现。
- 快速判断节点之间是否存在边: 判断节点
i和节点j之间是否存在边,只需要 O(1) 时间 访问matrix[i][j]即可。 - 稠密图 (Dense Graph) 适用: 当图中边的数量接近于节点数量的平方时(即图中大部分节点之间都存在边),邻接矩阵的空间效率相对较高。
缺点:
- 空间复杂度高: 邻接矩阵的空间复杂度为 O(n^2),n 为节点数量。 无论图的边数多少,都需要 n x n 的空间来存储矩阵。 对于 稀疏图 (Sparse Graph) (图中边的数量远小于节点数量的平方),邻接矩阵会浪费大量存储空间。
- 遍历效率低: 遍历一个节点的所有邻居节点,需要扫描邻接矩阵的一整行,时间复杂度为 O(n)。
邻接表 (Adjacency List):
邻接表 使用 链表 或 数组列表 (List) 来存储每个节点的邻居节点信息。 对于图中的每个节点
i,都维护一个列表,列表中存储节点i的 所有邻居节点。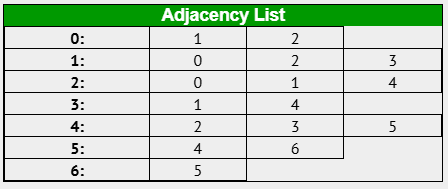
表示规则:
* 对于图中的每个节点,创建一个列表 (链表或数组列表)。
* 将该节点的所有邻居节点添加到该节点的列表中。
* 对于 有向图,节点i的列表中存储的是节点i指向 的节点(即出边指向的节点)。
* 对于 无向图,由于边是双向的,如果节点j是节点i的邻居,则节点i也是节点j的邻居。 因此,在表示无向图时,如果节点j出现在节点i的邻居列表中,则节点i也应该出现在节点j的邻居列表中。优点:
* 空间复杂度低: 邻接表的空间复杂度为 O(V + E),V 为节点数量,E 为边数量。 空间复杂度与图的边数成正比。 对于 稀疏图,邻接表可以节省大量存储空间,空间效率很高。
* 遍历效率高: 遍历一个节点的所有邻居节点,只需要遍历该节点的邻居列表,时间复杂度为 O(degree(v)),degree(v) 为节点的度(邻居节点数量)。缺点:
* 判断节点之间是否存在边效率较低: 判断节点i和节点j之间是否存在边,需要遍历节点i的邻居列表,时间复杂度为 O(degree(i))。 如果节点度很大,效率可能较低。
* 实现相对复杂: 邻接表的实现相对邻接矩阵稍复杂,需要使用链表或数组列表等数据结构。
选择邻接矩阵还是邻接表?
- 稠密图 (边多) -> 邻接矩阵: 虽然空间复杂度高,但实现简单,判断邻接关系快速。
- 稀疏图 (边少) -> 邻接表: 空间效率高,遍历效率高。
- 实际应用中,邻接表通常更常用, 因为现实世界中的很多图都是稀疏图,例如社交网络、Web 网络、交通网络等。
基本算法 (Basic Algorithms)
图论中有许多重要的算法,其中最基础和常用的两种图遍历算法是: 广度优先搜索 (BFS) 和 深度优先搜索 (DFS)。
图遍历算法用于系统地访问图中的所有节点,是很多图算法的基础。
广度优先搜索 (Breadth-First Search - BFS)
广度优先搜索 (BFS) 是一种 层序遍历 图的算法。 它从图的 起始节点 开始,逐层 地探索图的节点。 先访问起始节点的所有邻居节点,然后访问邻居节点的邻居节点,以此类推,一层一层地向外扩展,直到访问完所有可达节点。 BFS 类似于水波纹扩散,一层一层地向外蔓延。
算法步骤 (使用队列 Queue 实现):
a. 创建一个 队列 queue,用于存储待访问的节点。
b. 创建一个 集合 visited,用于记录已访问的节点,防止重复访问和无限循环。
c. 将 起始节点 start_node 加入队列 queue,并将 start_node 加入 visited 集合。
d. 当队列 queue 不为空 时,循环执行以下操作:
- 从队列
queue队首 取出一个节点current_node(出队)。 - 访问
current_node(例如,打印节点值、进行某种处理)。 - 遍历
current_node的 所有邻居节点neighbor:- 如果
neighbor未被访问过 (不在visited集合中): - 将
neighbor加入队列queue(入队)。 - 将
neighbor加入visited集合。
- 如果
e. BFS 结束。
代码示例:
1 | |
适用场景:
- 查找最短路径 (无权图): BFS 可以用来查找无权图中,从起始节点到其他节点的最短路径(路径包含的边数最少)。 因为 BFS 是按层遍历的,先访问到的节点距离起始节点更近。
- 社交网络关系查询: 例如,查找用户 A 的一度好友、二度好友等(一度好友是直接朋友,二度好友是朋友的朋友)。
- 网络爬虫: 网络爬虫可以使用 BFS 策略遍历 Web 页面,一层一层地抓取网页链接。
- 游戏地图搜索: 在游戏中,可以使用 BFS 查找从起点到终点的最短路径,例如在迷宫游戏中。
- 判断图的连通性: 从任意节点开始进行 BFS 遍历,如果遍历结束后
visited集合包含图中所有节点,则图是连通的。
深度优先搜索 (Depth-First Search - DFS)
深度优先搜索 (DFS) 是一种 递归地 探索图的算法。 它从图的 起始节点 开始,沿着一条路径 尽可能深地 探索下去,直到到达最深处 (无法继续前进) 或遇到已访问过的节点,然后 回溯 到上一个节点,再探索另一条路径。 DFS 类似于走迷宫,一条路走到黑,不行就退回,再换一条路。
算法步骤 (递归实现):
a. 创建一个 集合 visited ,用于记录已访问的节点。
b. 定义 递归函数 DFS(node) :
- 将当前节点
node标记为 已访问 ,并加入visited集合。 - 访问
node(例如,打印节点值、进行某种处理)。 - 遍历
node的 所有邻居节点neighbor:- 如果
neighbor未被访问过 (不在visited集合中):- 递归调用
DFS(neighbor),继续深入探索。
- 递归调用
- 如果
c. 从 起始节点 start_node 开始,调用 DFS(start_node) 启动深度优先搜索。
1 | |
算法步骤 (使用栈 Stack 实现,非递归):
a. 创建一个 栈 stack ,用于存储待访问的节点。
b. 创建一个 集合 visited ,用于记录已访问的节点。
c. 将 起始节点 start_node 压入栈 stack。
d. 当栈 stack 不为空 时,循环执行以下操作:
- 从栈
stack栈顶 弹出一个节点current_node(弹栈)。 - 如果
current_node未被访问过 (不在visited集合中):- 将
current_node标记为 已访问,并加入visited集合。 - 访问
current_node。 - 将
current_node的 所有邻居节点neighbor逆序压入栈stack(逆序压栈是为了保证先访问左边的邻居节点,再访问右边的邻居节点,如果邻居节点访问顺序有要求,则需要调整压栈顺序)。
- 将
1 | |
适用场景
- 路径查找: DFS 可以用来查找图中两个节点之间是否存在路径,或者查找所有可能的路径。
- 图的连通性判断: 与 BFS 类似,DFS 也可以用于判断图的连通性。
- 环检测: 可以使用 DFS 来检测图中是否存在环路。
- 拓扑排序: 对于有向无环图 (DAG),可以使用 DFS 来进行拓扑排序(将图中节点按依赖关系排序)。
- 迷宫求解: 可以使用 DFS 算法来求解迷宫问题,找到从起点到终点的路径。
- 树的先序遍历、中序遍历、后序遍历: 树的深度优先遍历(前序、中序、后序遍历)实际上就是 DFS 在树结构上的应用。
BFS vs DFS:
| 特性 | 广度优先搜索 (BFS) | 深度优先搜索 (DFS) |
|---|---|---|
| 搜索方式 | 层序遍历,逐层扩展 | 尽可能深入,回溯探索 |
| 数据结构 | 队列 (Queue) | 栈 (Stack) (或递归调用栈) |
| 空间复杂度 | 可能较高 (需要存储每层节点) | 通常较低 (只需存储当前路径节点) |
| 最短路径 | 擅长查找无权图最短路径 | 不擅长查找最短路径 (但可用于判断路径是否存在) |
| 应用场景 | 最短路径,层级关系,网络爬虫,广域搜索 | 路径查找,连通性,环检测,拓扑排序,深度探索 |
总结
图是一种非常灵活和强大的数据结构,可以用来表示各种复杂的关系网络。 理解图的概念、类型、表示方法、以及基本的图遍历算法(BFS 和 DFS),是学习更高级图算法和应用的基础。图论在计算机科学、数学、物理学、生物学、社会学等领域都有着广泛的应用,掌握图的相关知识,能够帮助你解决更多复杂的问题。